How MIT taught language models to read beyond their limits
Every AI language model, including those powering ChatGPT, Claude, and others, has a context window. Think of it as the AI’s working memory: how much text it can hold in mind at one time while answering a question.
Modern frontier models can handle roughly 200,000 words. That sounds like a lot, but a large legal contract, a hospital’s full patient records, or a software codebase can easily exceed that. Feed in too much text, and the AI can’t take it all in. Even when it fits, performance quietly degrades: details from the beginning get “forgotten” by the time the AI reaches the end. Researchers call this context rot.
Think of it like asking someone to memorise an entire encyclopaedia before answering your question. After a certain point, things they read earlier start slipping away.
The current solution is RAG
The most popular solution already in use is called Retrieval-Augmented Generation, or RAG. You’ve almost certainly interacted with a RAG-based system, which powers many enterprise chatbots, document Q&A tools, and AI assistants that claim to “search” your files. Popular NotebookLM is an example.
RAG works in two stages. First, a separate retrieval system (typically a vector database) pre-selects chunks it thinks are relevant to your question. Then those chunks are handed to the AI as context, and the AI answers based only on what the retriever chose to give it.
RAG has a fundamental problem: the retriever makes a single, static guess before the AI has even begun reasoning. It cannot adapt, go back for more, or explore connections the retriever didn’t anticipate. For simple lookups, it works well. For complex, multi-step questions across large document sets, it may fail.
What MIT built: Recursive Language Models (RLMs)
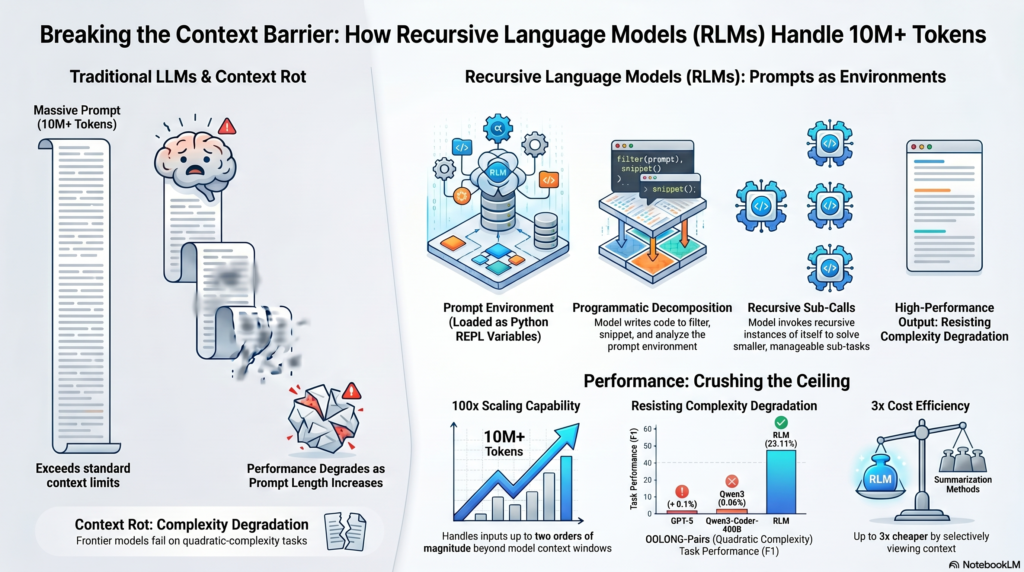
Researchers at MIT CSAIL, Alex Zhang, Tim Kraska, and Omar Khattab, published a paper in late 2025 introducing a fundamentally different approach. Instead of preselecting content before the AI thinks, they let the AI drive its own reading, in real time, as its reasoning evolves.
The document sits outside the AI in a programming environment. The AI writes code to search, scan, and extract exactly what it needs, when it needs it, and can spin up smaller AI helpers to analyse specific sections in parallel.
RAG
Retrieval-Augmented Generation
- A separate retrieval system pre-selects content before the AI starts thinking
- One retrieval shot, no going back if it guessed wrong
- AI only ever sees what the retriever decided to show it
- Struggles with questions that require many sources or evolving reasoning
RLM
Recursive Language Model
- The AI itself decides what to read, based on its own evolving reasoning
- Unlimited reads: searches adapt as new information is found
- Document never pre-indexed; AI accesses raw content directly
- Handles multi-hop, cross-document reasoning that RAG cannot
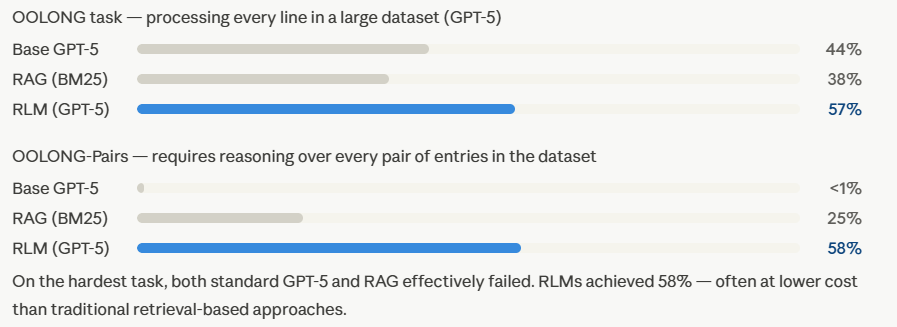
The paper tested RAG (with a BM25 retriever) directly against RLMs on a complex document task. RAG scored 51%. RLM scored 91%. The gap reflects a structural difference in how each approach handles reasoning that requires following a chain of clues across many sources.
How RLMs work, step by step
How well does it work?
The team tested RLMs using GPT-5 and a large open-source model across several challenging benchmarks. Results were most striking on tasks requiring the AI to process nearly every sentence in a huge document.
What’s still being worked on
RLMs are not perfect yet. Costs can spike unpredictably on hard tasks though they’re cheaper on average than summarisation-based alternatives. The AI sometimes wastes effort re-checking answers it has already found. Smaller models without strong coding ability struggle to use the programming environment effectively. And models not specifically trained to act as RLMs are inevitably less efficient than they could be — a promising direction for future work.
Can you use it
Not with your standard ChatGPT or Claude subscription and web interface.
You will need an API from ChatGPT or Claude. The code is available on GitHub. https://github.com/alexzhang13/rlm. You can set up using these, but be aware of the API cost.