Artificial intelligence has made remarkable progress in recent years. Tools like ChatGPT and Claude can explain complex topics, draft reports, and answer clinical questions with surprising fluency. But there is a fundamental problem that even the most sophisticated AI shares: it only knows what it was taught during training, and that training has a cutoff date.
This matters enormously in clinical microbiology. Antimicrobial resistance patterns shift. Guidelines are updated. New pathogens emerge. A model trained even six months ago may give you yesterday’s answer for today’s problem.
Two techniques, RAG (Retrieval-Augmented Generation) and CAG (Cache-Augmented Generation), have emerged as practical solutions. Neither requires retraining the AI from scratch. Instead, they extend what the AI can see at the moment you ask it a question.
Think of a large language model like a very well-read colleague who studied intensively for several years, then went into a sealed room with no internet or newspapers. Their knowledge is deep — but frozen in time. They cannot know what changed after they went in.
RAG and CAG are two different ways to pass documents under the door of that sealed room.
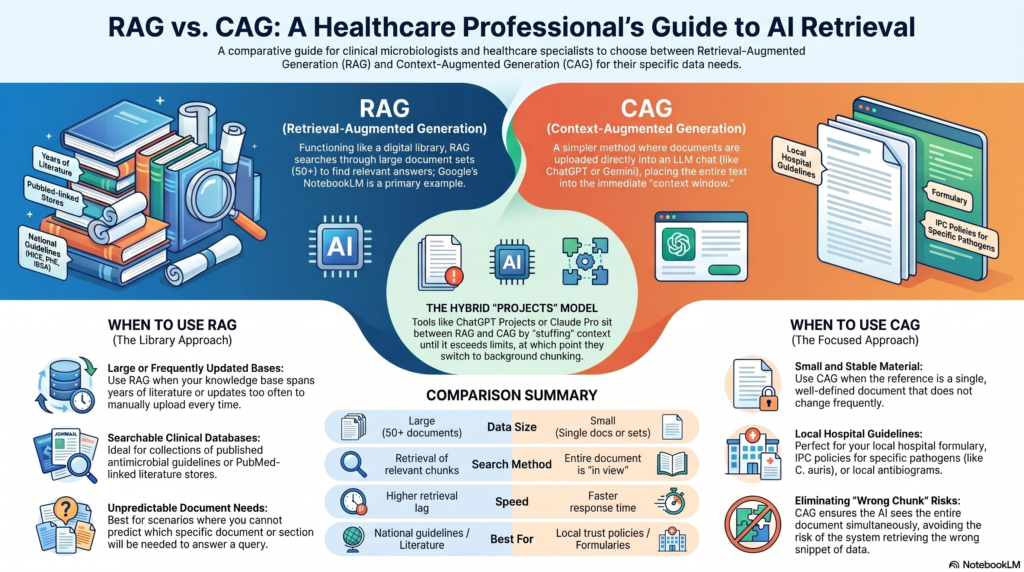
Retrieval-Augmented Generation (RAG)
RAG works like an open-book exam where the books are searched in real time. When you ask a question, the system first searches a database for the most relevant chunks of information, then hands those chunks to the AI alongside your question. The AI reads them and answers using both its training and the retrieved material.
Analogy: You are a registrar on call. You ask a question, and before answering, a very fast librarian retrieves the three most relevant pages from BNF, EUCAST, and your local policy, and places them on the desk in front of you.
RAG is well-suited to large, continuously updated knowledge bases, published literature, resistance surveillance data, or national guideline repositories. Its limitation is that the quality of the answer depends on whether the right chunks were retrieved. If the search pulls the wrong pages, the AI may still answer confidently, but from the wrong source.
Cache-Augmented Generation (CAG)
CAG takes the opposite approach. Instead of searching at query time, a document or a defined set of documents is loaded into the AI’s working memory in full before the conversation begins. The AI then has the entire document in view, all at once, with no retrieval step needed.
Analogy: Before your shift, you read your hospital’s antimicrobial policy cover to cover. When a query comes in during the shift, you are not searching; you already know every page of it.
CAG is ideal for smaller, stable, well-defined reference sets: a specific formulary, a single guideline, a resistance profile for a known outbreak strain. Its constraint is size – the AI’s context window can only hold so much text at once, making it unsuitable for very large or continuously changing knowledge bases.
RAG
Retrieval-Augmented Generation
- Searches dynamically at query time
- Best for large, live, or frequently updated databases
- Risk: wrong chunks retrieved → confident but wrong answer
- Speed: slower per query
CAG
Cache-Augmented Generation
- Pre-loads documents before the conversation begins
- Best for small, stable, well-defined reference sets
- Risk: context window limits how much can be loaded
- Speed: faster once loaded
These techniques are not mutually exclusive. Some systems combine both — using CAG to pre-load a core policy document, while using RAG to search a wider literature database for supplementary evidence.
In clinical microbiology
Microbiology sits at the intersection of rapidly evolving science and high-stakes clinical decisions. The MIC breakpoints that determine whether an isolate is sensitive or resistant can change year to year. Outbreak guidance is written in real time. A surveillance report from last quarter may already be outdated.
AI tools built without RAG or CAG will default to their training data when answering such queries, which may be months or years out of date, and which may not include your local resistance ecology, your institution’s formulary, or your regional outbreak context.
It must be remembered that RAG and CAG do not make AI infallible – the problem of not understanding the context, position bias or hallucinations still remains as risks. However, they represent a meaningful step toward an AI capable of operating in clinical environments where accuracy, fidelity, and specificity matter
As these tools become more integrated into diagnostic support, antimicrobial stewardship platforms, and laboratory information systems, understanding what they can and cannot do will be part of the clinical microbiologist’s working knowledge.
How can you use it?
Here is a practical guide to how a clinical microbiologist, an infection specialist, or a healthcare organisation might actually use these techniques today. For this I should give you some available systems where you can experience RAG and CAG.
Google’s NotebookLM is an example of RAG. Here you can upload a large number of documents (50 or more) and then use them as a library to generate your content or answer your questions. You can use this now.
An example of CAG is even simpler. When you open an LLM like ChatGPT/Claude/Gemini, you have an option to upload a document in the chat and ask a question from there. This is CAG. However, if you must be careful, as there is lmit of how big a document LLM can process. This is called context limit (token limit), so if you give a large document, LLM could make a mistake.
If you have ChatGPT or Claude Pro or above, you can access something called “projects”. You can upload a set of documents here and use it as your library. These are somewhere between RAG and CAG. They work by prepending your instructions and uploading documents directly into the context window at the start of each conversation. That is closer to CAG or more precisely, it is context stuffing / persistent context. However, there is a caveat: when document sets are large enough to exceed the context window, these platforms may apply chunking and retrieval behind the scenes. So the behaviour can shift depending on document size.
Ask the right question first.
Before choosing RAG or CAG, ask yourself: what knowledge does the AI need that it cannot possibly already have? The answer will point you to the right tool.
Here are some examples
Sepsis biomarker decision support — MetaSepsisKnowHub
A team in China built a RAG-powered platform indexing 427 sepsis biomarkers across 423 studies. When clinicians queried it, expert-reviewed recommendations scored significantly higher than answers from standalone GPT-4, GPT-4o, or Qwen2.5. The improvement was statistically significant (GPT-4 mean score rose from 75.8 to 81.6; p = 0.02). The key gain was that the AI could ground its sepsis management advice in current literature rather than its training snapshot alone. [Journal of Medical Internet Research – A Knowledge-Enhanced Platform (MetaSepsisKnowHub) for Retrieval Augmented Generation–Based Sepsis Heterogeneity and Personalized Management: Development Study]
Antimicrobial therapy decision support — KRAL system, Peking Union Medical College Hospital
Researchers at PUMCH built KRAL, an LLM enhanced with RAG over 750 pages of antimicrobial guidelines (dosing, renal adjustments, resistance patterns) and 710 de-identified patient cases. Against the PUMCH Antimicrobial benchmark, KRAL outperformed standard RAG by 27% on clinical reasoning tasks, at only 20% of the training cost of a fully fine-tuned model. This shows RAG over institutional guidelines is both effective and affordable for resource-constrained hospitals. [[2511.15974] KRAL: Knowledge and Reasoning Augmented Learning for LLM-assisted Clinical Antimicrobial Therapy]
Antibiotic prescribing safety — RAG-LLM across 12 clinical specialities
A multi-specialty study evaluated RAG-based LLMs (GPT-4, Gemini Pro, Med-PaLM 2) for identifying drug-related prescribing errors across 61 scenarios. RAG-LLM outperformed standalone LLMs across the board. Critically, when used in co-pilot mode — where the AI assists rather than replaces the clinician — accuracy, recall, and F1 scores were all optimised. This is now considered the preferred integration model for clinical settings. [[2402.01741] Development and Testing of a Novel Large Language Model-Based Clinical Decision Support Systems for Medication Safety in 12 Clinical Specialities]
Answering real clinical questions — RAG vs general-purpose LLMs
A head-to-head study tested five LLM systems against 50 real clinical questions reviewed by nine physicians. General-purpose LLMs (ChatGPT-4, Claude 3 Opus, Gemini Pro) produced relevant, evidence-based answers in only 2–10% of cases. RAG-based systems (e.g. OpenEvidence) answered appropriately in 24–58% of cases — a large and clinically meaningful gap. The conclusion: general LLMs, used as-is, are not fit for real-world clinical queries. [[2407.00541] Answering real-world clinical questions using large language model based systems]
Guideline interpretation, differential diagnosis, clinical trial screening — GPT-4 + RAG
A 2025 PMC narrative review summarised multiple published applications of RAG-enhanced GPT-4: interpreting hepatological guidelines, assisting with differential diagnosis, and screening patients for clinical trial eligibility. In all cases, RAG-grounded models outperformed ungrounded LLMs in accuracy and clinical plausibility, with particular gains where guideline text was dense and nuanced — exactly the kind of material found in infectious disease management. [Enhancing medical AI with retrieval-augmented generation: A mini narrative review – PMC]
Biomedical entity annotation in oncology research — GPT-4o + PubTator 3.0
Researchers developed a 4-step CAG pipeline using GPT-4o to annotate biomedical entities (pathogens, biomarkers, datasets) across 23 oncology research articles. The full article text was preloaded into the model’s context along with a metadata schema, and the AI was asked to identify entities against that schema in one pass — no retrieval step needed. The approach significantly reduced annotation time compared to manual expert review, with high precision verified in face-to-face expert interviews. [Identifying biomedical entities for datasets in scientific articles – A 4-step cache-augmented generation approach using GPT-4o and PubTator 3.0 | medRxiv]
CAG vs RAG for bounded knowledge tasks — benchmark study
The foundational CAG paper (published at ACM Web Conference 2025) compared CAG directly against RAG across multiple benchmarks. For tasks with a defined, manageable knowledge base — such as a single guideline document or local formulary — CAG matched or exceeded RAG performance while eliminating retrieval latency and retrieval errors entirely. The authors concluded that RAG’s complexity is unnecessary when all relevant knowledge fits within a long-context model’s window: the exact scenario that fits a local antibiogram, a single EUCAST version, or an institution’s IPC policy. [[2412.15605] Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks]
Machine learning applied to EUCAST breakpoints: Personalised aminopenicillin dosing using EUCAST breakpoints- machine learning proof-of-concept
A 2025 study trained XGBoost models to predict UTI diagnosis in patients with Enterobacterales bacteriuria and bacteraemia, then used EUCAST aminopenicillin breakpoints to generate personalised dosing recommendations. The result: 79–97% of patients received an appropriate aminopenicillin regimen, compared to a one-size-fits-all approach. This is a direct example of AI integrating clinical breakpoints — the kind of reference data that CAG could pre-load — to improve susceptibility reporting at the individual patient level. [Machine learning for personalized antimicrobial susceptibility breakpoints: (Adaptive clinical breakpoint interpretation) – PMC]